Snadnější shlukování nominálních dat díky balíčku Nomclust 2.0 z dílny akademiků FIS
Akademici z Fakulty informatiky a statistiky pod vedením Zdeňka Šulce vydali článek, ve kterém se věnují již druhé generaci balíčku Nomclust pro software R. Nomclust se zabývá hierarchickým shlukováním nominálních dat.
Nominální data jsou taková data, která obsahují kategoriální proměnné. Většinou jde alespoň o tři kategorie, u kterých nezáleží na pořadí. Jako příklad můžeme uvést např. místo narození nebo rodinný stav. Představme si databázi klientů, kterou máme charakterizovanou právě pomocí tohoto typu kategorií. Tyto klienty často potřebujeme roztřídit do skupin (shluků) tak, aby si byli jednotlivci v dílčích skupinách podobní a naopak se výrazně lišili v rozdílných skupinách. A proč klienty třídit? Takové roztřídění nám pomůže např. při zjišťování potřeb jednotlivých skupin klientů nebo při cílení marketingové kampaně. Se shlukováním si Nomclust 2.0 dokáže poradit – konkrétní metody balíčku popisují autoři v článku teoreticky i prakticky.
Proč se autoři rozhodli věnovat právě tomuto tématu? V aktuálním softwaru je hierarchické shlukování nominálních (kategoriálních) dat řešeno velmi omezeně. Běžně se v praxi využívá pouze jedna míra podobnosti (koeficient prosté shody), balíček Nomclust 2.0 kromě této základní míry nabízí dalších 11 alternativních měr podobnosti. Některé z nich zmiňovaný základní koeficient mnohdy překonávají, a je tak možné docílit lepších shluků. Nomclust 2.0 tak výrazně usnadňuje používání měr, které si běžný uživatel sám nenaprogramuje – akademické poznatky jsou tak dostupné pro všechny uživatele balíčku.
Nomclust 2.0 nabízí řešení i pro hodnocení kvality výsledných shluků. Při menším počtu objektů je dostatečné kvalitu shluků vyjádřit pomocí grafických výstupů, např. grafu dendrogram. Pokud je počet shlukovaných objektů vyšší, je třeba kvalitu shluků kvantifikovat. Díky tomu zjistíme, jaký počet shluků zvolit, popř. jestli není vhodnější vybrat jinou míru podobnosti. V balíčku je obsaženo osm hodnoticích kritérií speciálně navržených pro tento typ dat. Kritéria hodnotí kvalitu shluků z různých hledisek, což umožňuje uživateli vybrat vždy takové kritérium, které je nejvhodnější pro danou situaci.
Nomclust 2.0 nabízí funkcionalitu, kterou v jiných softwarových balíčcích nenajdeme. Balíček přináší nové míry podobnosti pro hierarchické shlukování nominálních dat nebo nové metody, jak lze kvalitu shluků hodnotit. Celkově je uživatelsky velmi přívětivý a přirozeně zapadne do zajeté workflow, výpočetní optimalizace v C++ zajišťují svižný chod programu, balíček navíc potěší i oko díky pěkným grafickým výstupům. Samozřejmostí je vysoká kompatibilita s ostatními funkcemi pro shlukování v softwaru R.
Celý článek si můžete přečíst v databázi Springer, samotný plně dokumentovaný balíček Nomclust 2.0 je k dispozici zdarma zde. Pokud by vás o balíčku zajímalo více informací, obraťte se přímo na autory článku – Zdeňka Šulce, Janu Cibulkovou nebo Hanu Řezankovou.
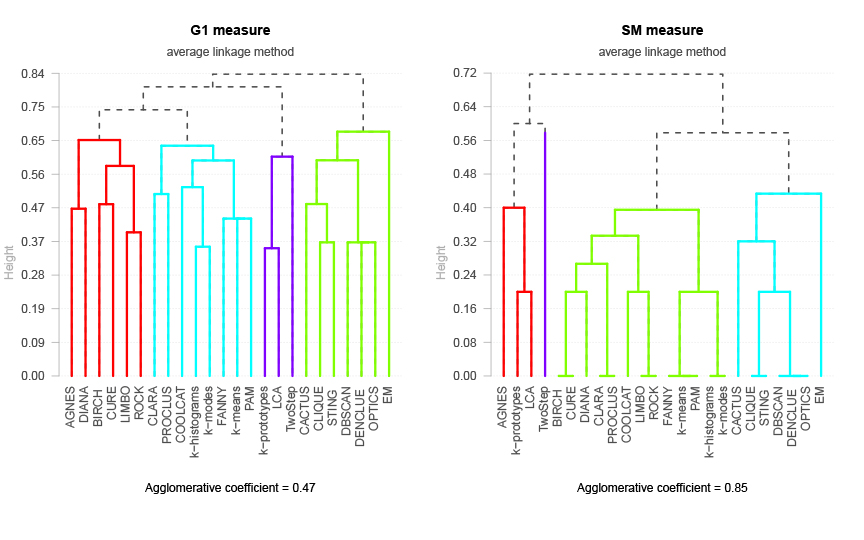
Obr. 1: porovnání dvou dendrogramů pro míry podobnosti G1 a SM na stejných datech (obsahujících vlastnosti různých shlukových algoritmů). Je vidět, že objekty mohou být rozděleny do různých skupin. Jednotlivé shluky jsou navíc odlišeny pomocí barev.
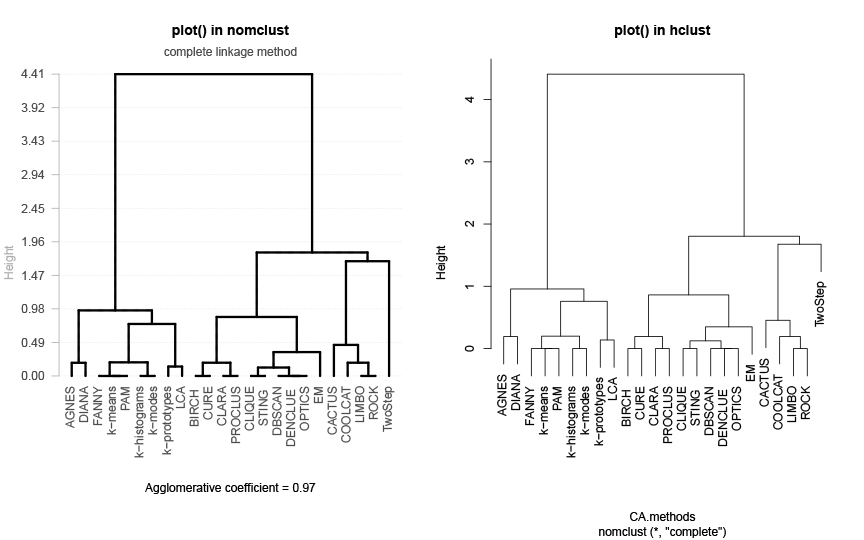
Obr. 2: porovnání grafických výstupů balíčku „nomclust“ a funkce „hclust“, která se často používá k hierarchickému shlukování objektů v R.
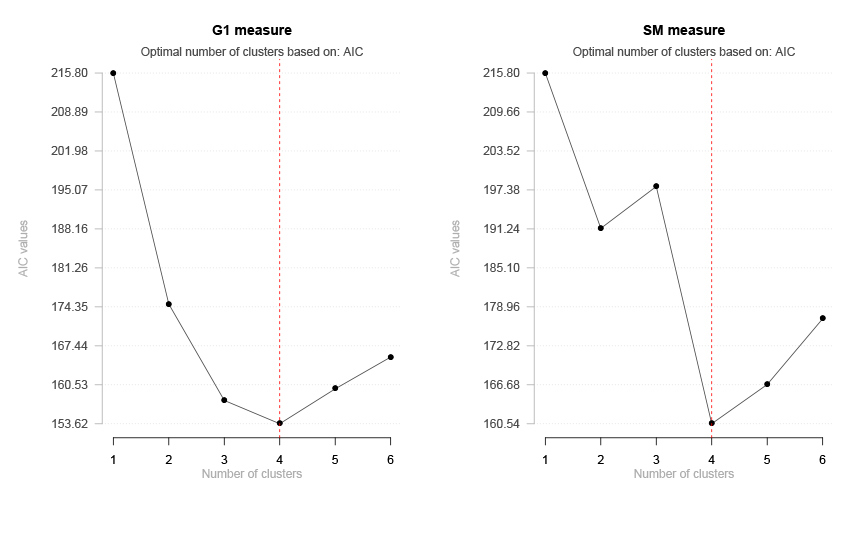
Obr. 3: Ukázka průběhu hodnoticích kritérií pro různé počty shluků (1 až 6). Pro toto konkrétní hodnoticí kritérium (AIC) značí optimální počet shluků nejnižší hodnota (je to navíc znázorněno červenou čárou). Tento graf také umožní výzkumníkovi s rozhodováním, který další počet shluků zvolit v případě, že „optimální“ počet shluků nevyhovuje. Např. u míry podobnosti G1 je to řešení se 3 shluky a u míry SM (koeficient prosté shody) 5 shluků.